

历经大约1年的规格制定工作后,由多家芯片、网通与云端服务大厂组成的UALink联盟,于2025年4月发表UALink(Ultra Accelerator Link)1.0版规范,让这项讨论已久的开放式加速器芯片互连I/O架构,终于正式问世。
UALink联盟成立于去年5月,成员包括AMD与Intel两大芯片厂商,加上Broadcom、Cisco两大网通厂商,还有Google、HPE、Meta与微软等云端大厂,阿里云、苹果与Synopsys也于2025年1月加入,理事会加上贡献者成员超过65家(但Broadcom已退出UALink理事会,降为一般贡献者成员)。联盟的宗旨是建立一个开放的GPU加速器互连I/O规范,为AI伺服器与丛集中的加速器,提供高速、低延迟的I/O连结架构,以对抗Nvidia的NVLink技术。
Nvidia当前在GPU加速器市场上的「霸业」,不仅是建立在GPU本身,还包括完整的周边应用架构,NVLink便是维系Nvidia「霸业」的「护城河」之一,Nvidia可以透过这套专属的高速I/O架构,让大量GPU彼此互连,建构出超大规模、超高密度的GPU运算环境。
单论个别GPU的运算效能规格,AMD与Intel的GPU往往不亚于Nvidia,部分特性甚至犹有过之,然而,现实环境大多需要多GPU协同运作,此时就会暴露出AMD与Intel各自的GPU互连I/O架构(如AMD的Infinity Fabric,与Intel的Xe Link),连结能力与频宽不如NVLink的问题,尤其是在跨GPU伺服器节点的情况下,连结的GPU数量越多,差距也越显著。
而UALink便是「非Nvidia阵营」抗衡NVLink的解决方案。 UALink最吸引人之处,是在Nvidia独家专属的NVLink技术之外,提供一套替代的开放式GPU互连I/O架构方案,还有多供应商参与带来的通用性与成本效益。
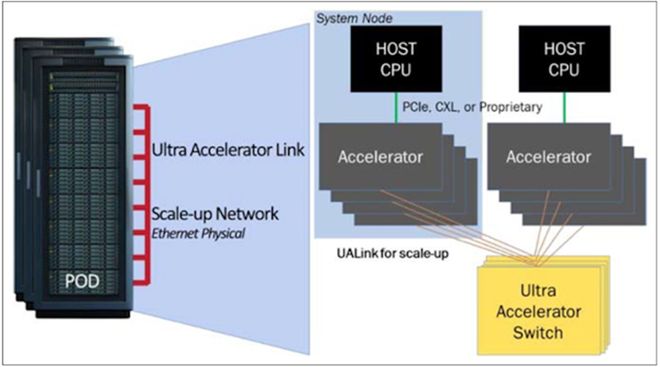
目前发布的UALink 1.0版规范,是基于乙太网路实体层的200G规格,可提供每通道100 Gb/s或200 Gb/s的传输速率,考虑到编码与纠错的损耗,实际信号速率为212.5 GT/s,可以1、2、4条通道组成1个链结(Link),在4通道下可提供800 Gb/s的资料传输频宽(也就是100 GB/s,双向为200 GB/s)。而透过UALink交换器(UALink Switch,ULS)的介接,可让最多1,024个GPU加速器互连,组成1个纵向扩展(Scale-Up)的AI Pod单元。
与NVLink相比,UALink 1.0的单一通道传输频宽更高,GPU互连规模更大,但个别GPU所能获得的总传输频宽,则较为逊色。
但NVLink 4.0与5.0可为每个GPU提供18个链结,一共36条传输通道,每个GPU能获得最大900 GB/s与1800 GB/s的总传输频宽(双向)。相较下,UALink 1.0只能为每个GPU提供800GB/s的总传输频宽(双向)。
目前看来,UALink 1.0的能力大致介于NVLink 4.0与NVLink 5.0之间,已有竞争能力,但产品推出时间是一弱点。BG大游官方网站BG大游官方网站
